서론
기술 면접에서 요구사항을 분석하고 테이블 설계를 진행했다. 그 과정에서 면접관님으로부터 지적을 받았고, 어떤 점이 잘못되었는지 찾아야 했지만 빠르게 파악하지 못했다.
ORM이나 ERD 툴에 너무 의존한 채 개발해 오면서, 평소에는 깊게 생각하지 않고 지나친 부분이 많았던 것 같다. 다음에는 같은 실수를 반복하지 않기 위해 학습한 내용을 정리한다.
문제 상황
과제에서 주어진 상황과 유사한 상황을 가정했다. 요구사항은 다음과 같다.
각 회원은 현재 시스템에 등록된 책을 찜 목록에 추가할 수 있다. 이때 같은 책을 여러 명이 찜할 수도 있다고 가정한다. 또한 같은 책을 중복해서 찜할 수는 없다. 사용자는 찜 목록을 확인하는 기능이 있다.
간단한 상황이라고 생각했고, 테이블을 아래 그림처럼 설계했다. 면접관님으로부터 현재 구조에는 문제가 있을 수 있다는 피드백을 받았지만, 긴장한 나머지 문제를 발견하지 못했다.
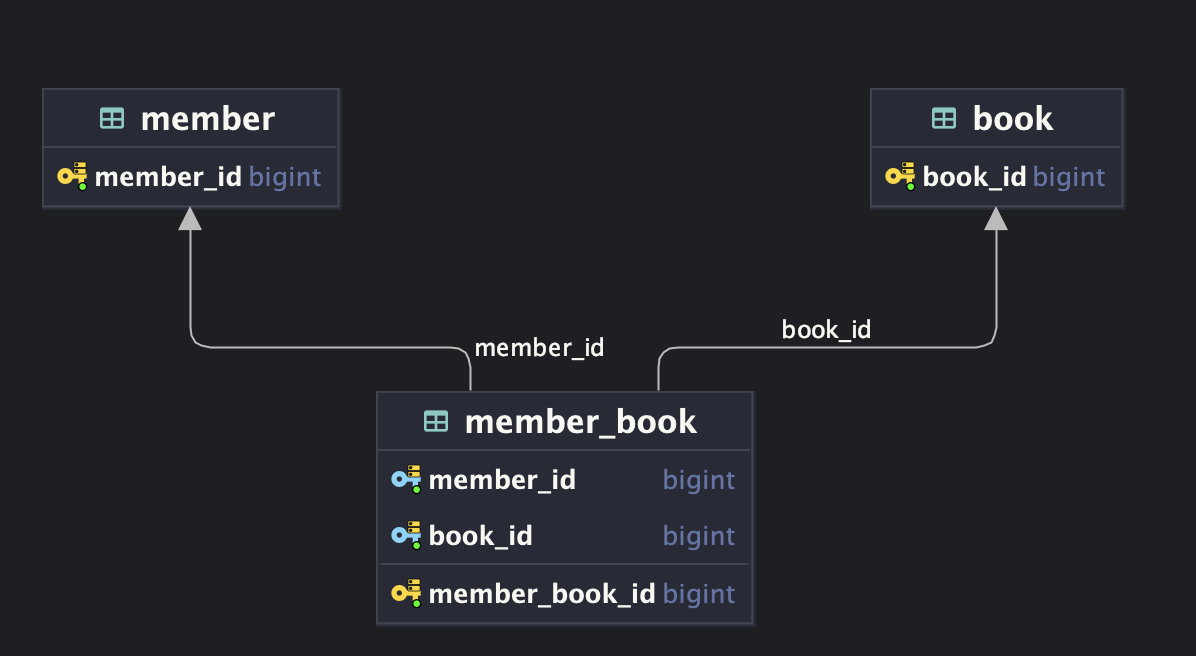
정답은 현재 구조라면 한 사용자가 같은 책을 중복해서 찜할 수 있다는 것이었다.
평소 JPA를 사용해 엔티티 관계를 정의했고, 다대다 관계는 아래처럼 구현해 왔다. 모든 엔티티에는 식별자가 있어야 한다고 생각했기 때문에 MemberBook 엔티티에는 PK 외에 member_id, book_id를 외래키로 두었다. 그리고 애플리케이션 단에서 이미 중복된 데이터가 저장되어 있는지 검사하도록 구현해 왔다.
뒤늦게 생각해 보니 이 부분이 실수였다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "member")
private List<MemberBook> memberBooks = new ArrayList<>();
...
}
@Entity
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
@OneToMany(mappedBy = "book")
private List<MemberBook> memberBooks = new ArrayList<>();
...
}
@Entity
public class MemberBook {
@Id @GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "book_id")
private Book book;
...
}
해결책: 복합키를 기반으로 유니크 인덱스 생성
아래 그림처럼 두 개의 외래키로 유니크 인덱스를 만들면 DB 레벨에서 유일성을 보장할 수 있다. 기존 테이블 구조를 수정했고, 왼쪽 다이어그램과 동일하게 칠판에 그렸다.
그런데 현재 테이블 구조라면 성능 문제가 있을 수 있다는 피드백을 또 받았다. 원인은 인덱스를 구성하는 컬럼의 순서를 고려하지 못한 것이었다.
[1] book_id, member_id 조합
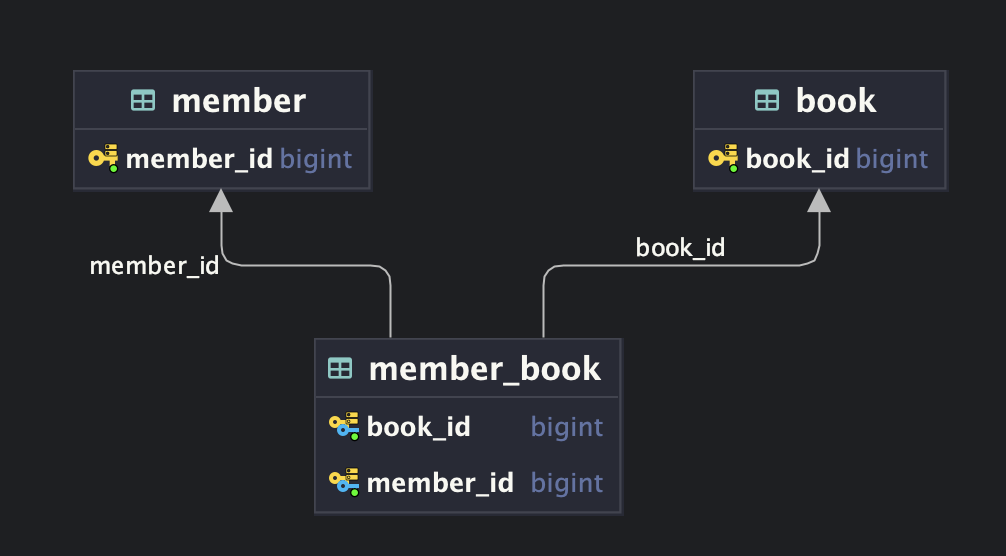
[2] member_id, book_id 조합
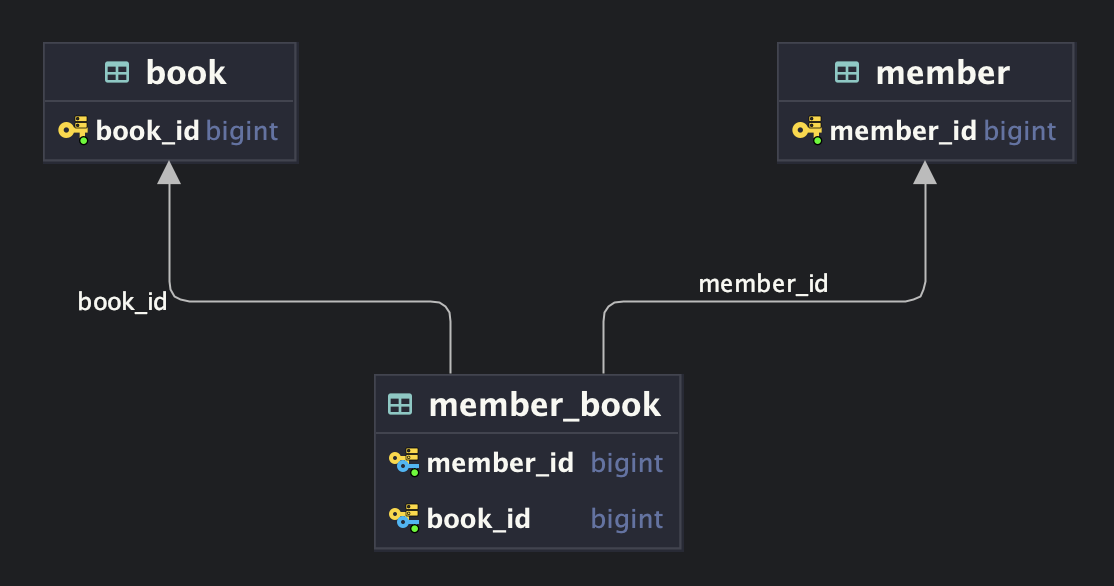
요구사항을 다시 떠올려 보면, 회원은 자신의 찜 목록을 조회할 수 있어야 한다. 만약 1번 구조로 테이블을 생성한다면 유니크 인덱스 순서 때문에 풀 테이블 스캔이 발생할 수 있다.
실제 두 테이블의 인덱스 키를 조회한 결과를 보면 Seq_in_index 값이 다르다.
[1]번 테이블의 인덱스
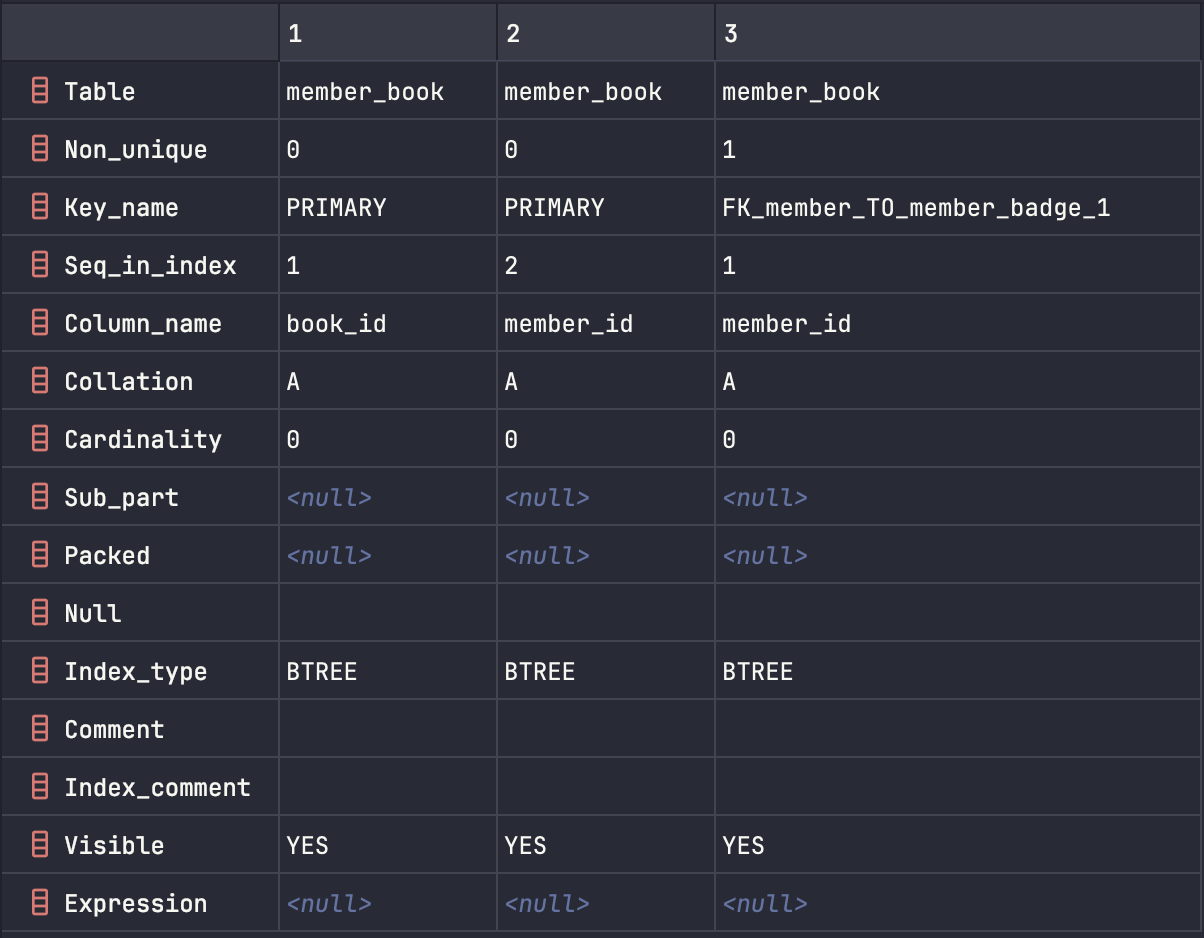
[2]번 테이블의 인덱스
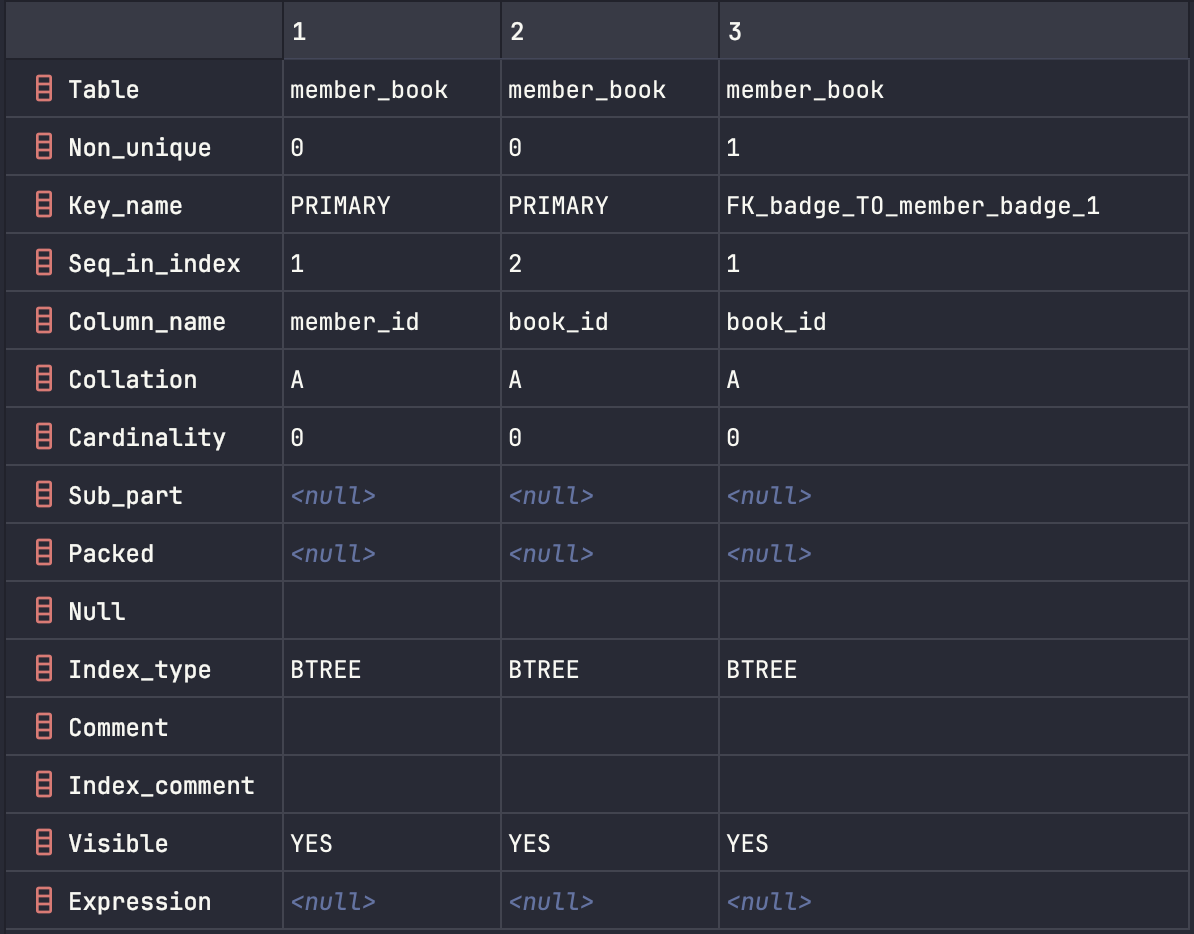
실제 데이터베이스에서 인덱스를 조회하면 Key_name = PRIMARY로 설정된 것은 좌우가 동일하다. 하지만 인덱스의 컬럼 순서는 각각 (book_id, member_id), (member_id, book_id)로 다르다.
인덱스는 정렬된 자료구조이기 때문에, 인덱스를 구성하는 컬럼의 순서가 중요하다. 아래 그림을 보면 dept_no를 기준으로 emp_no를 탐색하는 과정을 확인할 수 있다.
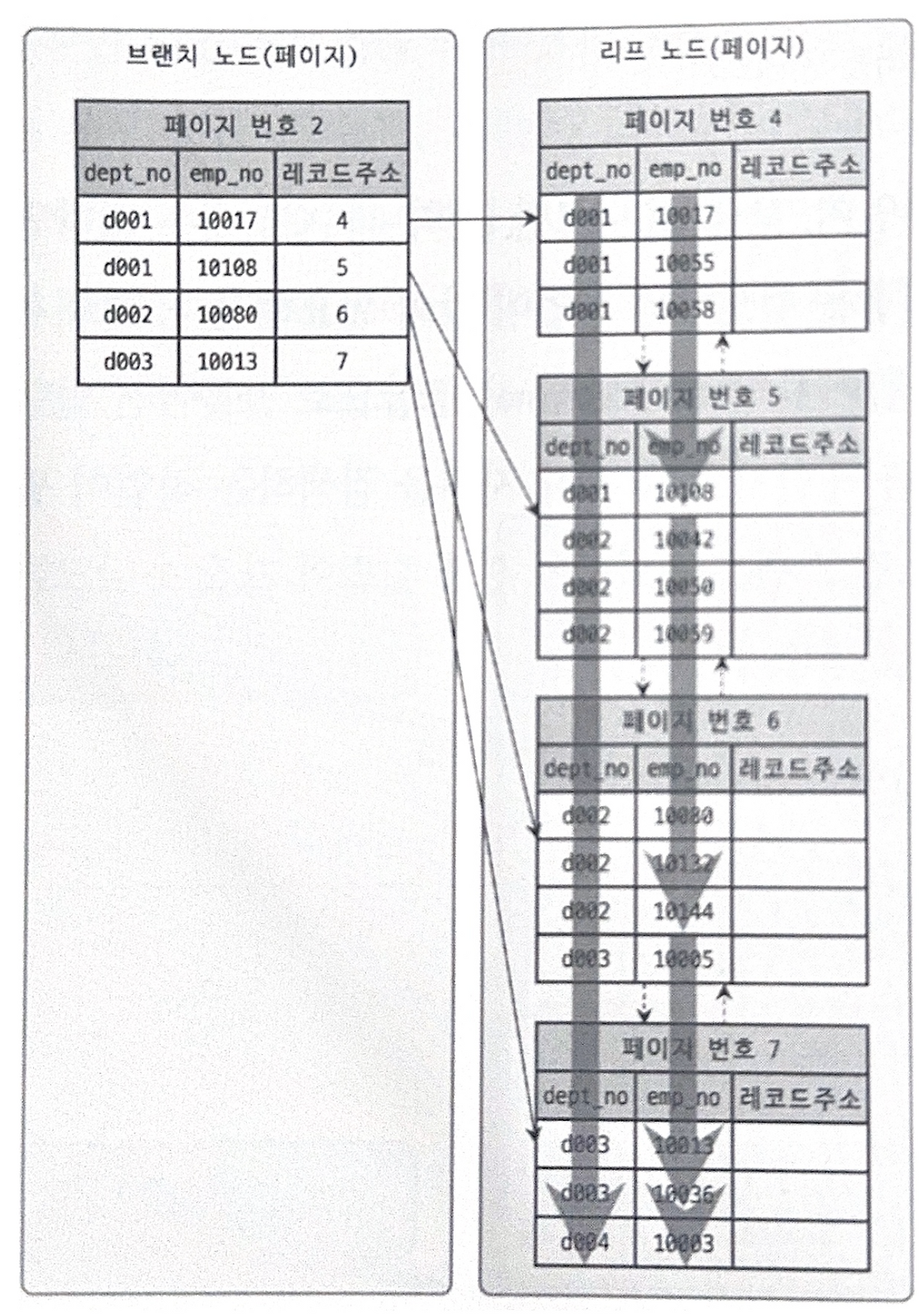
즉 (book_id, member_id) 조합으로 인덱스가 생성되면, member_id = 1인 찜 목록을 조회하기 위해 모든 인덱스를 탐색해야 하므로 성능 저하가 발생할 수 있다. 따라서 회원별 찜 목록 조회가 주요 요구사항이라면 (member_id, book_id) 순서로 복합 인덱스를 만들어야 한다.
최종적인 ERD 다이어그램은 다음과 같다.

-- MEMBER_BOOK 조인 테이블
CREATE TABLE `member_book` (
`book_id` BIGINT NOT NULL,
`member_id` BIGINT NOT NULL,
PRIMARY KEY (`member_id`, `book_id`), -- 실제 인덱스 순서가 결정되는 부분
CONSTRAINT `FK_member_TO_member_book_1`
FOREIGN KEY (`member_id`) REFERENCES `member` (`member_id`),
CONSTRAINT `FK_book_TO_member_book_1`
FOREIGN KEY (`book_id`) REFERENCES `book` (`book_id`)
);
마치며
물론 테이블 생성문에서 인덱스 순서를 직접 변경할 수도 있다. 하지만 실제 면접에서는 ERD 다이어그램에 표현된 내용 그대로 테이블이 만들어진다고 가정하신 것 같다.
순간적으로 꽤 디테일한 부분을 지적받아 당황했지만, 덕분에 새로운 내용을 배울 수 있었다. 이번 일을 계기로 ORM이나 ERD 툴이 만들어 주는 구조를 그대로 받아들이기보다, 실제 데이터베이스 관점에서 어떤 제약과 인덱스가 만들어지는지 함께 확인해야겠다고 느꼈다.
댓글