개요
데이터베이스 부하를 줄이기 위해 Redis 캐싱을 도입했다. 그러던 중 우연히 Cache Stampede 현상을 알게 되었다. 이 현상은 캐시에 저장된 많은 데이터가 동시에 만료되면서, 수많은 조회 요청이 데이터베이스로 몰리는 상황을 의미한다.
평소에는 깊게 생각하지 못했던 주제라 공부를 위해 관련 자료를 찾아봤다. 이 글에서는 트래픽이 많은 상황에서 데이터베이스 부하를 줄이기 위해 캐시를 어떻게 사용하면 좋을지 정리한다.
[1] Cache Stampede
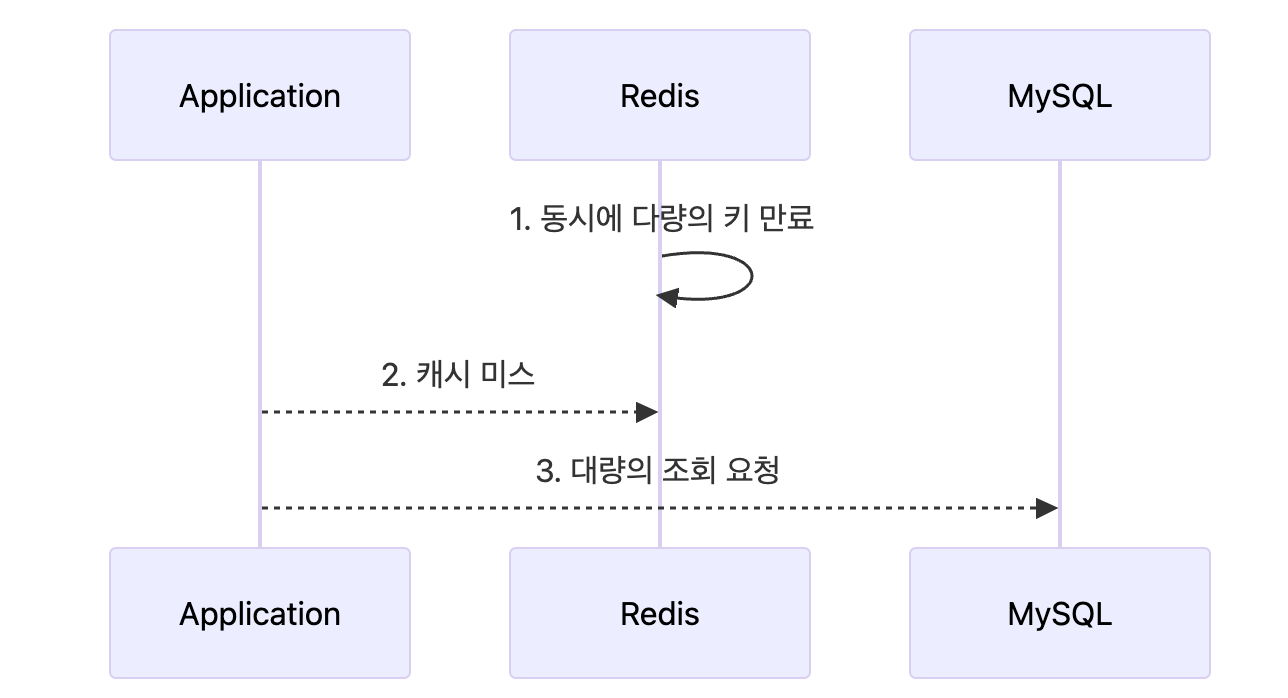
만약 24시간 주기로 캐시를 갱신하는 상황이라면, 매일 자정마다 트래픽이 데이터베이스로 몰릴 가능성이 있다.
해결법 : Jitter
지터는 네트워크에서 패킷 간 지연 시간이 일정하지 않고 불규칙하게 변하는 현상을 의미한다. 어떤 사용자가 1초마다 패킷을 보낸다고 가정하면, 실제로는 980ms, 1020ms처럼 도착까지 걸리는 시간이 조금씩 달라질 수 있다. 이런 지연 시간의 변화량을 Jitter라고 한다.
캐시에 저장하는 데이터에도 TTL을 설정한다. 이때 각각의 데이터마다 랜덤한 지연 시간을 추가하면 만료 시점이 분산되어 과도한 부하를 줄일 수 있다.
[2] Cache Penetration
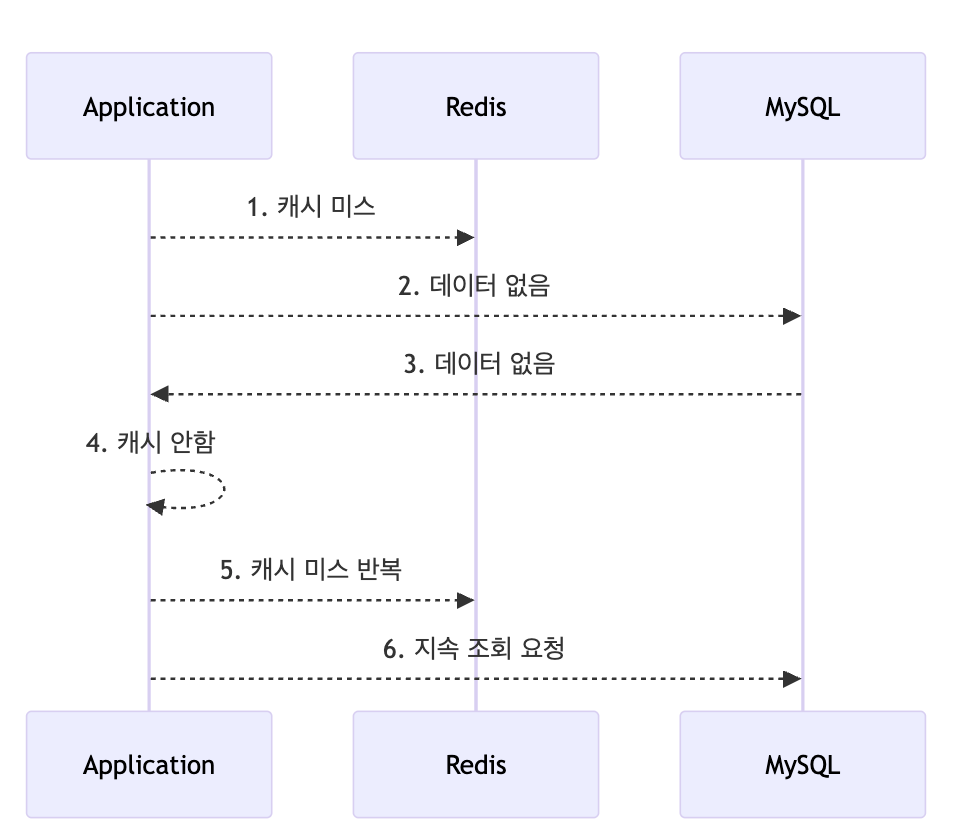
일반적으로 캐시에 저장된 값이 없어 null이 반환되면 데이터베이스를 조회하고, 조회한 값을 다시 캐시에 저장한다. 그런데 데이터베이스에도 해당 값이 없어 null이 반환되면 캐시에 값을 저장하지 못한다. 이 경우 같은 요청이 반복될 때마다 데이터베이스를 조회하는 문제가 발생할 수 있다.
해결법 : Null Object Pattern
값이 없음 자체를 캐싱하는 방법이다. 캐시에 저장하는 타입을 상속받아 값의 부재를 의미하는 클래스 타입을 저장한다. 상속을 사용하지 않고 같은 타입의 객체를 사용할 수도 있지만, 이 경우 클래스 내부 필드에 쓰레기 값을 저장하고 애플리케이션에서 별도로 예외 처리할 수도 있다.
public interface Notify {
void send();
}
public class EmailNotify implements Notify {
public void send() {
System.out.println("send email");
}
}
// NULL 객체
public class NullNotify implements Notify {
public void send() {
// Do Nothing
}
}
이처럼 다형성을 활용하면 null을 직접 반환하지 않아 반복되는 조회 요청을 막을 수 있다.
[3] 캐시 시스템 장애
Redis 서버에 문제가 생겨 동작하지 않는 상황이 발생할 수 있다. 트래픽이 적은 상황이라면 데이터베이스로 요청을 전달해 데이터를 조회하고 서비스를 제공할 수 있다.
하지만 트래픽이 많은 상황에서는 데이터베이스 부하로 인해 서비스 운영에 문제가 생길 수 있다. 잘못하면 캐시가 꼭 필요하지 않은 서비스까지 함께 운영하지 못하는 상황이 발생할 수 있다.
해결책 : Failover
시스템을 설계할 때 핵심 기능을 정의하고, 캐시 시스템 문제로 인한 피해를 최소화해야 한다. 캐시 서버를 복구하는 동안 관련 기능은 일시적으로 막고, 다른 서비스는 계속 이용할 수 있도록 하는 방식이다.
캐시 시스템이 죽었을 때 데이터베이스로 fallback하는 코드를 작성하기는 쉽다. 하지만 데이터베이스 부하가 발생하더라도 반드시 동작해야 하는 기능인지 먼저 따져볼 필요가 있다.
댓글